|
|

|

|
| e-Pub |
Section: New Results
Enhancing Pre-defined Event Models Using Unsupervised Learning
Participants : Serhan Coşar, François Brémond.
keywords: Pre-defined activity models, unsupervised learning, tailoring activity models
In this work, we have developed a new approach to recognize human activities from videos, given models that are learned in an unsupervised way and that can take advantage of a priori knowledge provided by an expert of the application domain. The description-based methods use pre-defined models and rules to recognize concrete events. But, if the data has unstructured nature, such as daily activities of people, the models cannot handle the variability in data (e.g., the way of preparing meal is person dependent).
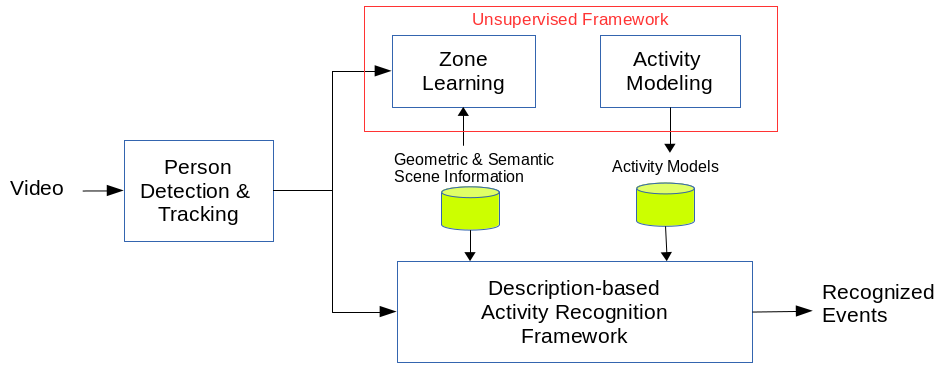
In order to overcome this drawback, we have combined the description-based method in [66] with an unsupervised activity learning framework, as presented in Figure 31 . We have created a mutual knowledge loop system, in which both frameworks are combined in a way to compensate their individual limitations. In [66] , scene regions are pre-defined and the activity models are created via defining an expected duration value (e.g., 2 seconds) and a posture type (e.g., standing) by hand. Thus, these hand-crafted models fail to cover the variability in data and require an update by experts whenever the scene or person changes. To automatically define these parameters, we utilize the unsupervised activity recognition framework. The unsupervised approach first learns scene regions (zones) in the scene using trajectory information and then, it learns the duration and posture distribution for each zone. By matching the pre-defined zones with learned zones, we connect the learned parameter distributions with hand-crafted models.
The knowledge is passed in a loopy way from one framework to another one. By knowledge we mean: (i) the geometric information and scene semantics of the description-based system are used to label the zones that are learned in an unsupervised way, (ii) the activity models that are learned in an unsupervised way are used to tune the parameters (i.e. tailoring) in the activity models of the description-based framework. It is assumed that the person detection and tracking are already performed and we have the trajectory information of people in the scene beforehand.
|
We have tested the performance of the knowledge-loop based framework on two datasets: i) Hospital-RGB, ii) Hospital-RGBD. Each dataset contains one person performing everyday activities in a hospital room. The activities considered in the datasets are ”watching TV“, ”preparing tea“, ”answering phone“, ”reading newspaper/magazine“, ”watering plant“, ”organizing the prescribed drugs“, ”writing a check at the office desk“ and ”checking bus routes in a bus map“. Each person is recorded using RGB and RGBD cameras of 640480 pixels of resolution. RGB dataset consists of 41 videos and RGBD dataset contains 27 videos. For each person, video lasts approximately 15 minutes.
The performance of the approach in [66] with hand-crafted models and our approach with learned models for Hospital-RGB and Hospital-RGBD datasets are presented in Table 9 and in Table 10 . The results have been partially presented in Ellomiietcv2014 (waiting hal acceptation). It can be clearly seen that updating the constraints in activity models using data learned by the unsupervised approach enables us to detect activities missed by the pre-defined models. For ”watching TV“ and ”using pharmacy basket“ activities in RGB dataset and ”answering phone“ and ”preparing tea“ activities in RGBD dataset, there is increase in false positive rates. The reason is that, for some activities, the duration and posture distributions learned by the unsupervised approach can be inaccurate because of other actions occurring inside a zone (e.g., a person standing inside tea zone and reading). For this reason, the constraints updated in activity models are too wide and other activities that occur inside the zone are also detected. Despite the small increase of false positives in some activities, we have increased the true positive rates and obtained sensitivity rates around 90% and 87% on average in RGB and RGBD datasets, respectively, and precision rates around 81% on average in RGBD dataset. Thanks to the distributions learned for time duration and posture, we can enhance the activity models that are manually defined in the description-based, and thereby detect missed events.
| Hand-crafted Models | Unsupervised Models | |||
| ADLs | Sensitivity (%) | Precision (%) | Sensitivity (%) | Precision (%) |
| Answering Phone | 70 | 82.35 | 95 | 90.47 |
| Watching TV | 84.61 | 78.57 | 100 | 54.16 |
| Using Office Desk | 91.67 | 47.82 | 91.67 | 52.38 |
| Preparing Tea | 80.95 | 70.83 | 76.19 | 80 |
| Using Phar. Basket | 100 | 90.90 | 100 | 76.92 |
| Watering Plant | 100 | 81.81 | 88.89 | 88.89 |
| Reading | 45.46 | 83.34 | 81.82 | 90 |
| TOTAL | 81.81 | 76.52 | 90.5 | 76.11 |
| Hand-crafted Models | Unsupervised Models | |||
| ADLs | Sensitivity (%) | Precision (%) | Sensitivity (%) | Precision (%) |
| Answering Phone | 80 | 100 | 84.21 | 88.89 |
| Watching TV | 55.56 | 45.46 | 77.78 | 58.34 |
| Preparing Tea | 100 | 73.68 | 92.85 | 65 |
| Using Phar. Basket | 100 | 90 | 100 | 100 |
| Watering Plant | 40 | 66.67 | 83.34 | 71.42 |
| Reading | 100 | 66.67 | 71.42 | 83.34 |
| Using Bus Map | 50 | 71.42 | 100 | 100 |
| TOTAL | 75.07 | 73.41 | 87.08 | 80.99 |